《并发设计模式》第29章-生产者消费者模式-生产者消费者模式在线程池中的应用
作者:冰河
星球:http://m6z.cn/6aeFbs
博客:https://binghe.site
文章汇总:https://binghe.site/md/all/all.html
源码获取地址:https://t.zsxq.com/0dhvFs5oR
沉淀,成长,突破,帮助他人,成就自我。
- 本章难度:★★☆☆☆
- 本章重点:了解生产者消费者模式的使用场景,重点掌握生产者消费者模式在线程池中的应用,并能够结合自身项目实际场景思考如何将生产者消费者模式灵活应用到自身实际项目中。
大家好,我是冰河~~
线程池不仅仅是面试过程中的高频考点,在日常工作中,也是经常被使用到的。所以,线程池对于程序员来说,还是比较重要的。并且在线程池的实现中,使用了生产者消费者模式。如果能在面试中基于生产者消费者模式熟练的说出线程池的执行流程,那无疑就是加分项,并且在平时的工作中,对线程池的理解越深刻,越不容易出现各种诡异的Bug问题。
一、前言
在前面的文章中,我们基于生产者消费者模式简单模拟实现了面向C端的个人文库系统,并且按照细分化的场景系统的讲解了使用生产者消费者模式开发实际项目时,可能会产生的消息堆积问题,同时,根据不同的业务场景介绍了消息堆积问题的解决方案。
其实,JDK中的线程池在实现的过程中,就使用了生产者消费者模式。本章,接介绍下线程池中对生产者消费者模式的应用。
二、线程池执行流程
首先,我们再来看看线程池的总体执行流程,如图29-1所示。
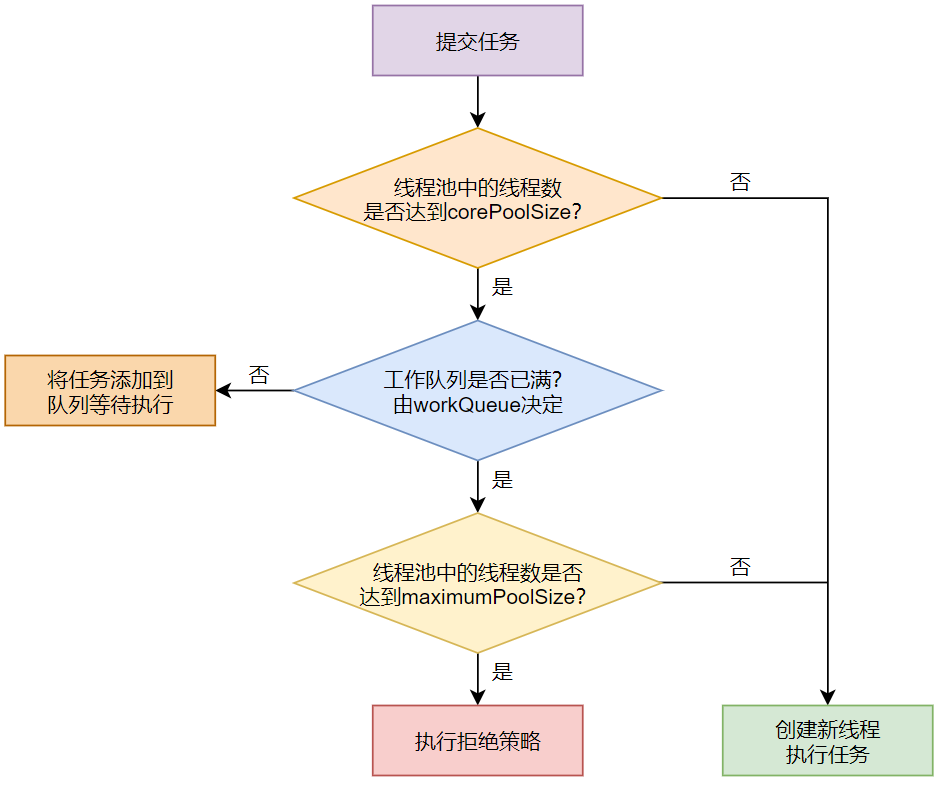
可以看到,当向线程池中提交任务时,线程池执行任务的流程如下所示。
(1)向线程池提交任务时,首先会判断线程池中的线程数是否已经达到corePoolSize,如果线程池中的线程数未达到corePoolSize,则直接创建新线程执行任务。否则,进入步骤(2)。
(2)判断线程池中的工作队列是否已满,如果线程池中的工作队列未满,则将任务添加到队列中等待执行。否则,进入步骤(3)。
(3)判断线程池中的线程数是否已经达到maximumPoolSize,如果线程池中的线程数未达到maximumPoolSize,则直接创建新线程执行任务。否则,进入步骤(4)。
(4)执行拒绝策略。
注意:关于线程池的拒绝策略,大家可以参考《第17章:两阶段终止模式在线程池中的应用》的内容,这个不再赘述。
三、线程池的创建
在JDK中,实现线程池最核心的类就是ThreadPoolExecutor,通过ThreadPoolExecutor类的构造方法,可以创建对应的线程池。既然Executors类中提供的创建线程池的方法中,大部分调用的都是ThreadPoolExecutor类的构造方法,因此,可以直接调用ThreadPoolExecutor类的构造方法来创建线程池,而不再使用Executors工具类。这也是阿里巴巴开发手册中推荐的创建线程池的方式。
通过查看ThreadPoolExecutor类的源码可知,ThreadPoolExecutor类中提供的构造方法如下所示。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
通过对ThreadPoolExecutor类源码的分析可知,通过ThreadPoolExecutor类创建线程池时最终调用的构造方法如下所示。
查看全文
加入冰河技术知识星球,解锁完整技术文章与完整代码
