《高性能SQL引擎》总结-高性能SQL引擎整体专栏总结
作者:冰河
星球:http://m6z.cn/6aeFbs
博客:https://binghe.site
文章汇总:https://binghe.site/md/all/all.html
源码获取地址:https://t.zsxq.com/0dhvFs5oR
专栏汇总地址:https://articles.zsxq.com/id_tx01uwlh582w.html
沉淀,成长,突破,帮助他人,成就自我。
- 本节难度:★★☆☆☆
- 本节重点:对高性能SQL引擎进行整体回顾和总结,从全局视角了解高性能SQL引擎的设计和架构思想,重点掌握高性能SQL引擎基于通用数据模型和通用数据模板动态生成SQL的核心流程,并能够将其灵活应用到自身实际项目中。
大家好,我是冰河~~
经过这些天的坚持,《高性能SQL引擎》终于接近尾声了,感谢大家这些天的坚持与陪伴,也相信大家在《高性能SQL引擎》项目和专栏中,学到了不少知识、技术与架构思想。接下来,我们就一起对《高性能SQL引擎》专栏做个总结。
这里,会涉及到很多互联网大厂研发过程中所使用的核心技术和架构设计模式,也有冰河在互联网大厂工作过程中,自主研发和深度参与基础软件和基础中间件架构设计和研发过程中所使用到的核心架构模式和核心技术,更重要的是,项目中积累了冰河在解决大厂基础架构问题和灵活多变的复杂业务问题的经验。

在《高性能SQL引擎》项目中,你学到的不仅仅是一个自动生成SQL的引擎项目,更重要的是要学会大厂处理高并发、大流量场景的技术方案和架构设计思想以及处理灵活多变的复杂业务问题的经验,并学会如何将这些技术方案和架构设计思想落地到实际项目中。
一、项目背景
曾几何时,冰河还在大厂基础数据部门做数据与中台相关的架构设计时,每天面对着灵活多变的复杂查询场景,例如:各种报表分析、日志数据分析、用户行为分析、用户画像与各种维度分析、广告埋点数据分析、商品分析、大促、营销数据与场景分析等等。这些数据查询与分析,如果没有一个通用的基础设施解决方案,根本是行不通的。
试想,在各种灵活多变的复杂查询和分析场景下,如果只是采用传统的CRUD模式,搭建常规的CRUD业务系统提供业务接口查询,那对于业务层的代码实现是相当复杂的,并且传统业务层的设计再灵活,也难以满足各种灵活复杂的业务场景。

随着基础数据越来越庞大,数据分析场景越来越多,业务层的架构设计也会越来越复杂,业务层的代码也会越来越复杂,在这些背景的加持下,数值分析部门提出一个查询分析需求时,业务层的实现要过比较长的一段时间才能满足需求,严重影响了数据分析的及时性,也在一定程度上影响了公司乃至集团的战略决策。

所以,在为了摆脱这种困境,冰河开始调研和实践一种行之有效的方案,经过各种尝试和实践,终于探索出一种行之有效的落地方案——自研高性能SQL引擎项目,经过在公司的落地实践证明,方案完全可行,业务层几乎不用改动即可满足灵活多变的复杂查询业务场景。
二、专栏结构
《高性能SQL引擎》项目虽然规模不大,属于中间件组件类项目,但是却能在实际工作中,面对高并发、复杂且灵活多变的业务场景时,发挥着极其重要的作用。
在整个《高性能SQL引擎》项目和专栏中,我们从需求设计、总体架构和通用模型设计开始,一路带着大家对高性能SQL引擎中最基础和最核心的内容进行设计和编码实现。整体专栏内容如下所示。
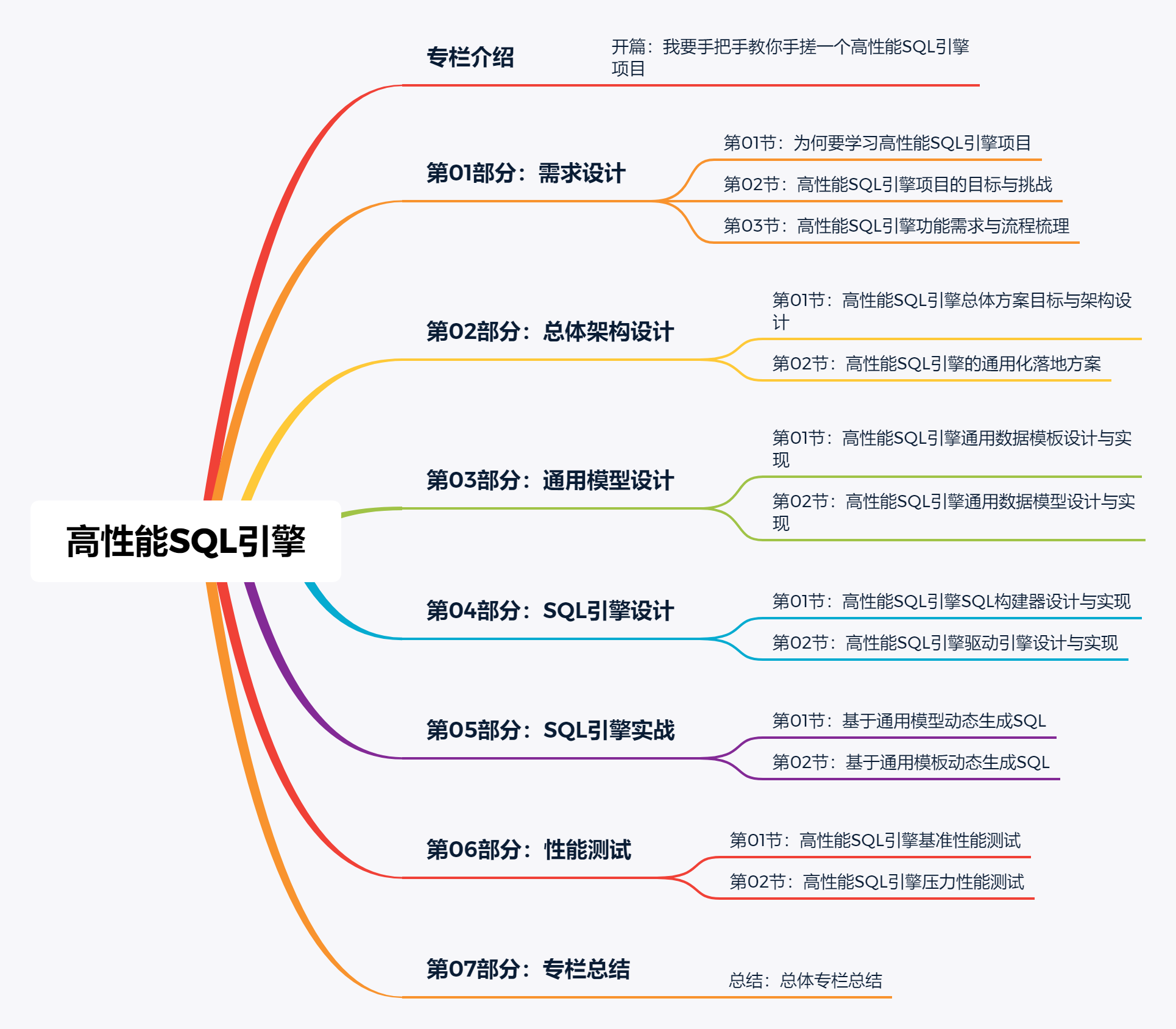
整体专栏分为 8个大的篇章、15篇核心技术文章(每篇文章都会录制对应的视频课程),每篇文章对应一个源码分支 ,以便让大家更好的对应专栏、视频和小册进行学习。
总之,《高性能SQL引擎》整体课程采用视频+小册+源码+1v1问答形式,加入星球即可加入专属交流群,并且星球提供了简历优化服务,还为大家准备了1000+精美简历模板,助力小伙伴们升职加薪,让你在面试过程中更具竞争力。加入星球,猛戳如下链接获取1000+精美简历模板。
三、技术选型
这次带着大家一起手写的高性能SQL引擎项目去除了各种复杂的场景校验逻辑,在代码结构上非常精简,核心功能就是通过JSON模板或者直接创建对象组合动态生成SQL,不再依赖各种实体模型来接收和传递数据。代码精简,意味着性能会非常高,同时,也意味着使用到的技术也会非常简单。主要的技术选型如下:
- 基础工具:Hutool
- 单元测试:Junit
- 基准性能测试:JMH
- 压力测试:JMeter
没错,这次的高性能SQL引擎项目所使用到的技术就是这么简单。
四、适应人群
很长一段时间内,星球的小伙伴也经常问冰河,在各种灵活复杂的查询业务场景下,如何能够有效的减少业务层的改动来适应这种灵活多变的业务场景。另外,很多小伙伴在和冰河交流的过程中,也普遍存在如下几个问题:

- 刚毕业,想快速提升自己,快速积累复杂业务经常经验,但不知从何学起。
- 校招、社招没什么拿的出手的项目,投出的简历石沉大海。
- 一直在小公司做CRUD,根本接触不到灵活多变的复杂业务场景,更别说为这些场景提供解决方案了。
- 公司项目没什么并发,在线人数也不多,积累的数据量根本就不多,只是简单的CRUD就能满足需求。
- 学了很多高并发和高性能的知识,也知道一些概念,能说出一些简单的方案,但是没实际项目经验。
- 自我感觉掌握了一些高并发、高性能编程的技术方案,但是在真正做项目时,还是不知道如何下手。
- 想做一些高并发、高性能相关的中间件和业务项目,根本不知道怎么做,更别提架构设计和研发了。
- 简历上写了数据分析项目,在面试过程中,面试官一般会问数据分析的实现原理和底层架构设计,或者其他数据分析通用解决方案相关的问题,不知道怎么回答。
- 在大厂工作多年,参与了一些系统的建设与研发,但是也没机会参与支持灵活多变的复杂业务场景的高性能通用基础中间件的建设过程。
- 业务场景灵活且复杂,但没有行之有效的方案解决灵活多变的业务场景问题。
- 其他问题。。。
从冰河自身角度来说,是为了解决公司实际场景问题,而自研高性能SQL引擎项目。从各位小伙伴们的反馈来看,小公司的小伙伴受限于业务,接触不到高并发、大流量的复杂业务场景,大厂的小伙伴由于某些原因没有被分到高并发、大流量的复杂业务场景部门。又有些小伙伴是正在经历灵活且复杂的业务场景,但没有行之有效的方案解决灵活多变的业务场景问题。

所以,如果你正在被如上问题所困扰,不妨跟冰河一起学习下高性能SQL引擎项目,向前迈出一步,或许困扰你的问题就被迎刃而解。
五、实战效果
高性能SQL引擎支持根据通用数据模型和通用数据模板动态生成SQL,这里,再次给出10种典型的通过高性能SQL引擎生成SQL语句的案例场景。各位小伙伴可以根据自身实际需要,生成任意自己想要的SQL语句。
5.1 案例一:普通查询
查询用户表中用户id为1的用户信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.EQ).fieldValue("1").build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "=",
"fieldValue": "1"
}]
}
生成的SQL语句如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id = 1
5.2 案例二:in查询
查询用户表中用户id在1,2,3,4中的用户信息
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.IN).fieldValue("1,2,3,4").build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "in",
"fieldValue": "1,2,3,4"
}]
}
生成的SQL语句如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id IN ( 1, 2, 3, 4 )
5.3 案例三:like查询
查询用户表中名字包含小的用户信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_name").middleConditions(Constants.LIKE).fieldValue("'%小%'").build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_name",
"aboveConditions": "and",
"middleConditions": "like",
"fieldValue": "'%小%'"
}]
}
生成的SQL如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_name LIKE '%小%'
5.4 案例四:between-and查询
查询用户表中用户id在1~100之间的用户信息.
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}]
}
生成的SQL如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id BETWEEN 1
AND 100
5.5 案例五:分页查询
分页查询用户信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// SQL分页限制
Limit limit = Limit.builder().pageStart(0).pageSize(10).databaseType(0).build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).limit(limit).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}],
"limit": {
"pageStart": 0,
"pageSize": 10,
"databaseType": 0
}
}
生成的SQL语句如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id BETWEEN 1
AND 100
LIMIT 0,
10
5.6 案例六:降序查询
降序查询用户信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// SQL语句的排序部分
OrderBy orderBy = OrderBy.builder().fields(Arrays.asList("user_id")).sort(Constants.DESC).build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).orderBy(Arrays.asList(orderBy)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}],
"orderBy": [{
"fields": ["user_id"],
"sort": "desc"
}]
}
生成的SQL语句如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id BETWEEN 1
AND 100
ORDER BY
user_id DESC
5.7 案例七:多组排序查询
对用户进行多组排序查询。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句要查询的字段
List<String> fields = Arrays.asList("user_id", "user_name", "address", "sex", "remark");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// SQL语句的排序部分
OrderBy desc = OrderBy.builder().fields(Arrays.asList("user_id", "user_type")).sort(Constants.DESC).build();
OrderBy asc = OrderBy.builder().fields(Arrays.asList("province_id", "country_id")).sort(Constants.ASC).build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).fields(fields).condition(List.of(condition)).orderBy(Arrays.asList(desc, asc)).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["user_id", "user_name", "address", "sex", "remark"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}],
"orderBy": [{
"fields": ["user_id", "user_type"],
"sort": "desc"
}, {
"fields": ["province_id", "country_id"],
"sort": "asc"
}]
}
生成的SQL语句如下所示。
SELECT
user_id,
user_name,
address,
sex,
remark
FROM
t_user AS USER
WHERE
user_id BETWEEN 1
AND 100
ORDER BY
user_id,
user_type DESC,
province_id,
country_id ASC
5.8 案例八:分组聚合查询
分组聚合查询用户信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句聚合查询部分
Aggregation userIdAggregation = Aggregation.builder().field("user_id").aggregationMode(AggregationEnum.DISTINCT_COUNT.getName()).alias("userCount").build();
Aggregation amountAggregation = Aggregation.builder().field("amount").aggregationMode(AggregationEnum.SUM.getName()).alias("totalAmount").build();
// 分组查询字段
List<String> groupByFields = Arrays.asList("province_id", "user_type");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).aggregation(Arrays.asList(userIdAggregation, amountAggregation)).condition(Arrays.asList(condition)).groupBy(groupByFields).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"fields": ["province_id", "user_type"],
"aggregation": [{
"field": "user_id",
"aggregationMode": "DISTINCT_COUNT",
"alias": "userCount"
}, {
"field": "amount",
"aggregationMode": "SUM",
"alias": "totalAmount"
}],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}],
"groupBy": ["province_id", "user_type"]
}
生成的SQL语句如下所示。
SELECT
province_id,
user_type,
count( DISTINCT user_id ) AS userCount,
sum( amount ) AS totalAmount
FROM
t_user AS USER
WHERE
user_id BETWEEN 1
AND 100
GROUP BY
province_id,
user_type
5.9 案例九:子查询
通过子查询统计用户的相关信息。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
// SQL语句要查询的数据表
Table table = Table.builder().tableName("t_user").alias("user").build();
// SQL语句聚合查询部分
Aggregation userIdAggregation = Aggregation.builder().field("user_id").aggregationMode(AggregationEnum.DISTINCT_COUNT.getName()).alias("userCount").build();
Aggregation amountAggregation = Aggregation.builder().field("amount").aggregationMode(AggregationEnum.SUM.getName()).alias("totalAmount").build();
List<Aggregation> aggregations = Arrays.asList(userIdAggregation, amountAggregation);
// 分组查询字段
List<String> groupByFields = Arrays.asList("province_id", "user_type");
// 子查询的表
Table subTable = Table.builder().tableName("t_user").alias("sub_user").build();
// 子查询字段
List<String> subFields = Arrays.asList("user_id", "amount", "province_id", "user_type");
// SQL语句的条件
Condition condition = Condition.builder().aboveConditions(Constants.AND).field("user_id").middleConditions(Constants.BETWEEN).fieldValue("1,100").build();
// 子查询条件
Join join = Join.builder().table(subTable).joinType(JoinEnum.QUERY_SUBSYSTEM.toString()).fields(subFields).condition(Arrays.asList(condition)).build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table).aggregation(aggregations).joins(Arrays.asList(join)).groupBy(groupByFields).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "t_user",
"alias": "user"
},
"joins": [{
"joinType": "QUERY_SUBSYSTEM",
"table": {
"tableName": "t_user",
"alias": "sub_user"
},
"fields": ["user_id", "amount", "province_id", "user_type"],
"condition": [{
"field": "user_id",
"aboveConditions": "and",
"middleConditions": "between",
"fieldValue": "1,100"
}]
}],
"fields": ["province_id", "user_type"],
"aggregation": [{
"field": "user_id",
"aggregationMode": "DISTINCT_COUNT",
"alias": "userCount"
}, {
"field": "amount",
"aggregationMode": "SUM",
"alias": "totalAmount"
}],
"groupBy": ["province_id", "user_type"]
}
生成的SQL如下所示。
SELECT
province_id,
user_type,
count( DISTINCT user_id ) AS userCount,
sum( amount ) AS totalAmount
FROM
( SELECT user_id, amount, province_id, user_type FROM t_user AS sub_user WHERE user_id BETWEEN 1 AND 100 ) AS sub_user
GROUP BY
province_id,
user_type
5.10 案例十:关联查询
对用户分析表和支付分析表进行关联分析查询。
通过高性能SQL引擎的通用模型动态生成SQL的代码如下所示。
//SQL数据表
Table table = Table.builder().tableName("user_analysis").alias("user_analysis").build();
// 表1聚合条件
Aggregation agg1Table1 = Aggregation.builder().field("register_count").alias("register_count")
.aggregationMode(AggregationEnum.SUM.getName()).build();
Aggregation agg1Table2 = Aggregation.builder().field("login_count").alias("login_count")
.aggregationMode(AggregationEnum.SUM.getName()).build();
// 表1查询条件
Condition condition1 = Condition.builder().aboveConditions(Constants.AND).field("analysis_date")
.middleConditions(Constants.GE).fieldValue("2000-01-01").build();
// 表1关联条件
Join join1 = Join.builder().table(table).aggregation(Arrays.asList(agg1Table1, agg1Table2))
.condition(Arrays.asList(condition1)).fields(Arrays.asList("analysis_date", "analysis_type", "platform_id"))
.groupBy(Arrays.asList("analysis_date", "analysis_type", "platform_id"))
.joinType(JoinEnum.QUERY_SUBSYSTEM.toString()).build();
// 表2
Table table2 = Table.builder().tableName("pay_analysis").alias("pay_analysis").build();
// 表2聚合条件
Aggregation agg2Table1 = Aggregation.builder().field("pay_count").alias("pay_count")
.aggregationMode(AggregationEnum.SUM.getName()).build();
Aggregation agg2Table2 = Aggregation.builder().field("change_count").alias("change_count")
.aggregationMode(AggregationEnum.SUM.getName()).build();
// 表2查询条件
Condition condition2 = Condition.builder().aboveConditions(Constants.AND).field("analysis_date")
.middleConditions(Constants.GE).fieldValue("2000-01-01").build();
// 连接表条件
Condition joinCondition1 = Condition.builder().aboveConditions(Constants.AND).field("user_analysis.analysis_date")
.middleConditions(Constants.EQ).fieldValue("pay_analysis.analysis_date").build();
Condition joinCondition2 = Condition.builder().aboveConditions(Constants.AND).field("user_analysis.analysis_type")
.middleConditions(Constants.EQ).fieldValue("pay_analysis.analysis_type").build();
Condition joinCondition3 = Condition.builder().aboveConditions(Constants.AND).field("user_analysis.platform_id")
.middleConditions(Constants.EQ).fieldValue("pay_analysis.platform_id").build();
// 表2关联条件
Join join2 = Join.builder().table(table2).aggregation(Arrays.asList(agg2Table1, agg2Table2))
.condition(Arrays.asList(condition2)).fields(Arrays.asList("analysis_date", "analysis_type", "platform_id"))
.groupBy(Arrays.asList("analysis_date", "analysis_type", "platform_id")).joinType(JoinEnum.LEFT.toString())
.joinCondition(Arrays.asList(joinCondition1, joinCondition2, joinCondition3)).build();
Aggregation agg1 = Aggregation.builder().field("register_count").alias("registerCount")
.aggregationMode(AggregationEnum.SUM.getName()).build();
Aggregation agg2 = Aggregation.builder().field("login_count").alias("loginCount")
.aggregationMode(AggregationEnum.SUM.getName()).build();
Aggregation agg3 = Aggregation.builder().field("pay_count").alias("payCount")
.aggregationMode(AggregationEnum.SUM.getName()).build();
Aggregation agg4 = Aggregation.builder().field("change_count").alias("changeCount")
.aggregationMode(AggregationEnum.SUM.getName()).build();
// 构造通用模型
SqlParams sqlParams = SqlParams.builder().table(table)
.aggregation(Arrays.asList(agg1, agg2, agg3, agg4))
.joins(Arrays.asList(join1, join2))
.groupBy(Arrays.asList(
"user_analysis.analysis_date",
"user_analysis.analysis_type",
"user_analysis.platform_id",
"pay_analysis.analysis_date",
"pay_analysis.analysis_type",
"pay_analysis.platform_id")).build();
// 生成SQL
String sql = SqlEngine.getSql(sqlParams);
// 打印结果
System.out.println("生成的SQL===>>>" + sql);
构造出的高性能SQL引擎的查询数据模板如下所示。
{
"table": {
"tableName": "user_analysis",
"alias": "user_analysis"
},
"joins": [{
"joinType": "QUERY_SUBSYSTEM",
"table": {
"tableName": "user_analysis",
"alias": "user_analysis"
},
"fields": ["analysis_date", "analysis_type", "platform_id"],
"aggregation": [{
"field": "register_count",
"aggregationMode": "SUM",
"alias": "register_count"
}, {
"field": "login_count",
"aggregationMode": "SUM",
"alias": "login_count"
}],
"condition": [{
"field": "analysis_date",
"aboveConditions": "and",
"middleConditions": ">=",
"fieldValue": "2000-01-01"
}],
"groupBy": ["analysis_date", "analysis_type", "platform_id"]
}, {
"joinType": "LEFT",
"table": {
"tableName": "pay_analysis",
"alias": "pay_analysis"
},
"fields": ["analysis_date", "analysis_type", "platform_id"],
"aggregation": [{
"field": "pay_count",
"aggregationMode": "SUM",
"alias": "pay_count"
}, {
"field": "change_count",
"aggregationMode": "SUM",
"alias": "change_count"
}],
"condition": [{
"field": "analysis_date",
"aboveConditions": "and",
"middleConditions": ">=",
"fieldValue": "2000-01-01"
}],
"joinCondition": [{
"field": "user_analysis.analysis_date",
"aboveConditions": "and",
"middleConditions": "=",
"fieldValue": "pay_analysis.analysis_date"
}, {
"field": "user_analysis.analysis_type",
"aboveConditions": "and",
"middleConditions": "=",
"fieldValue": "pay_analysis.analysis_type"
}, {
"field": "user_analysis.platform_id",
"aboveConditions": "and",
"middleConditions": "=",
"fieldValue": "pay_analysis.platform_id"
}],
"groupBy": ["analysis_date", "analysis_type", "platform_id"]
}],
"fields": ["user_analysis.analysis_date", "user_analysis.analysis_type", "user_analysis.platform_id", "pay_analysis.analysis_date", "pay_analysis.analysis_type", "pay_analysis.platform_id"],
"aggregation": [{
"field": "register_count",
"aggregationMode": "SUM",
"alias": "registerCount"
}, {
"field": "login_count",
"aggregationMode": "SUM",
"alias": "loginCount"
}, {
"field": "pay_count",
"aggregationMode": "SUM",
"alias": "payCount"
}, {
"field": "change_count",
"aggregationMode": "SUM",
"alias": "changeCount"
}],
"groupBy": ["user_analysis.analysis_date", "user_analysis.analysis_type", "user_analysis.platform_id", "pay_analysis.analysis_date", "pay_analysis.analysis_type", "pay_analysis.platform_id"]
}
生成的SQL语句如下所示。
SELECT
user_analysis.analysis_date,
user_analysis.analysis_type,
user_analysis.platform_id,
pay_analysis.analysis_date,
pay_analysis.analysis_type,
pay_analysis.platform_id,
sum( register_count ) AS registerCount,
sum( login_count ) AS loginCount,
sum( pay_count ) AS payCount,
sum( change_count ) AS changeCount
FROM
(
SELECT
analysis_date,
analysis_type,
platform_id,
sum( register_count ) AS register_count,
sum( login_count ) AS login_count
FROM
user_analysis AS user_analysis
WHERE
analysis_date >= '2000-01-01'
GROUP BY
analysis_date,
analysis_type,
platform_id
) AS user_analysis
LEFT JOIN (
SELECT
analysis_date,
analysis_type,
platform_id,
sum( pay_count ) AS pay_count,
sum( change_count ) AS change_count
FROM
pay_analysis AS pay_analysis
WHERE
analysis_date >= '2000-01-01'
GROUP BY
analysis_date,
analysis_type,
platform_id
) AS pay_analysis ON user_analysis.analysis_date = pay_analysis.analysis_date
AND user_analysis.analysis_type = pay_analysis.analysis_type
AND user_analysis.platform_id = pay_analysis.platform_id
GROUP BY
user_analysis.analysis_date,
user_analysis.analysis_type,
user_analysis.platform_id,
pay_analysis.analysis_date,
pay_analysis.analysis_type,
pay_analysis.platform_id
六、如何学习
1.加入 冰河技术 知识星球(文末有知识星球优惠券,高性能Polaris网关项目已完结,即将涨价),才能查看星球专栏文章,学习专栏视频课程,查看星球置顶消息,申请加入项目,才能看到项目代码和技术小册,如果未申请加入项目,点击项目链接,你会发现是404页面。
2.专栏的每一章会对应一个代码分支,学习视频和专栏文章时,大家对照代码分支学习即可。
3.学习过程中最好按照章节顺序来学习,每一章前后都是比较连贯的,并且每一章的代码实现也有先后顺序,这样按照从前往后的顺序学习,最终你会实现一个完整的高性能SQL引擎项目。
注意:学习的过程,不是复制粘贴代码的过程,赋值粘贴代码是没有任何意义的,最好的学习方式就是自己动手实现代码,然后思考、总结。
4.代码结构:master分支是最新的全量代码,专栏中每一个章节和视频都会对应一个代码分支,切换到章节对应的代码分支后,即可根据当前章节和视频学习对应的代码实现,不然,在master分支中看到的是全量的代码。
5.对应代码实现上的问题,可以在专栏对应的源码提issuse
6.冰河会为《高性能SQL引擎》专栏录制完整的视频课程。
六、写在最后
在冰河的知识星球除了高性能SQL引擎项目外,还有其他11个项目,像DeepSeek大模型、手写高性能Polaris网关、手写高性能熔断组件、手写通用指标上报组件、手写高性能数据库路由组件、分布式IM即时通讯系统、Sekill分布式秒杀系统、手写RPC、简易商城系统等等,这些项目的需求、方案、架构、落地等均来自互联网真实业务场景,让你真正学到互联网大厂的业务与技术落地方案,并将其有效转化为自己的知识储备。
值得一提的是:冰河自研的Polaris高性能网关比某些开源网关项目性能更高,并且冰河也正在为企业级高性能RPC框架录制视频,全程带你分析原理和手撸代码。 你还在等啥?不少小伙伴经过星球硬核技术和项目的历练,早已成功跳槽加薪,实现薪资翻倍,而你,还在原地踏步,抱怨大环境不好。抛弃焦虑和抱怨,我们一起塌下心来沉淀硬核技术和项目,让自己的薪资更上一层楼。
目前,领券加入星球就可以跟冰河一起学习《DeepSeek大模型》、《手写高性能Polaris网关》、《手写高性能RPC项目》、《分布式Seckill秒杀系统》、《分布式IM即时通讯系统》《手写高性能通用熔断组件项目》、《手写高性能通用监控指标上报组件》、《手写高性能数据库路由组件项目》、《手写简易商城脚手架项目》、《Spring6核心技术与源码解析》和《实战高并发设计模式》,从零开始介绍原理、设计架构、手撸代码。
花很少的钱就能学这么多硬核技术、中间件项目和大厂秒杀系统与分布式IM即时通讯系统,比其他培训机构不知便宜多少倍,硬核多少倍,如果是我,我会买他个十年!
加入要趁早,后续还会随着项目和加入的人数涨价,而且只会涨,不会降,先加入的小伙伴就是赚到。
另外,还有一个限时福利,邀请一个小伙伴加入,冰河就会给一笔 分享有奖 ,有些小伙伴都邀请了50+人,早就回本了!
七、其他方式加入星球
- 链接 :打开链接 http://m6z.cn/6aeFbs 加入星球。
- 回复 :在公众号 冰河技术 回复 星球 领取优惠券加入星球。
特别提醒: 苹果用户进圈或续费,请加微信 hacker_binghe 扫二维码,或者去公众号 冰河技术 回复 星球 扫二维码加入星球。
好了,今天就到这儿吧,我是冰河,我们下期见~~
