一次线上服务GC耗时长的排查经历
大家好,我是冰河~~
今天给大家分享一篇生产环境服务触发GC耗时长问题的排查经历,希望大家能够从中获取实质性的帮助。
又一个可直接应用于生产环境的监控组件项目完结并上线,点击链接:https://t.zsxq.com/LjMTj 快速学习,并可直接应用于你的生产环境项目。
简介
最近,我们系统配置了GC耗时的监控,但配置上之后,系统会偶尔出现GC耗时大于1s的报警,排查花了一些力气,故在这里分享下。
发现问题
我们系统分多个环境部署,出现GC长耗时的是俄罗斯环境,其它环境没有这个问题,这里比较奇怪的是,俄罗斯环境是流量最低的一个环境,而且大多数GC长耗时发生在深夜。
发现报警后,我立马查看了GC日志,如下:
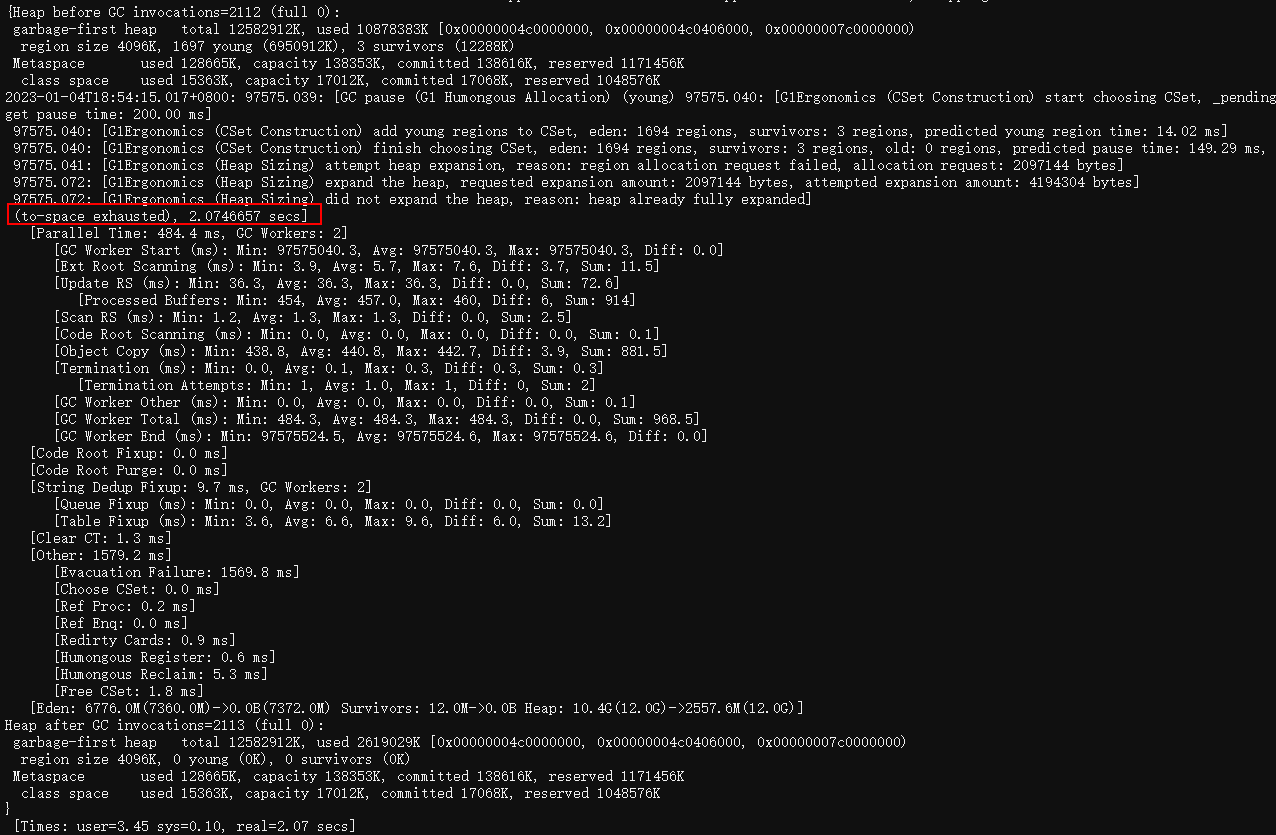
日志中出现了to-space exhausted,经过一番了解,出现这个是由于g1在做gc时,都是先复制存活对象,再回收原region,当没有空闲空间复制存活对象时,就会出现to-space exhausted,而这种GC场景代价是非常大的。
同时,在这个gc发生之前,还发现了一些如下的日志。

这里可以看到,系统在分配约30M+的大对象,难道是有代码频繁分配大对象导致的gc问题。
定位大对象产生位置
jdk在分配大对象时,会调用G1CollectedHeap::humongous_obj_allocate方法,而使用async-profiler可以很容易知道哪里调用了这个方法,如下:
# 开启收集
./profiler.sh start --all-user -e G1CollectedHeap::humongous_obj_allocate -f ./humongous.jfr jps
# 停止收集
./profiler.sh stop -f ./humongous.jfr jps
将humongous.jfr文件用jmc打开,如下:
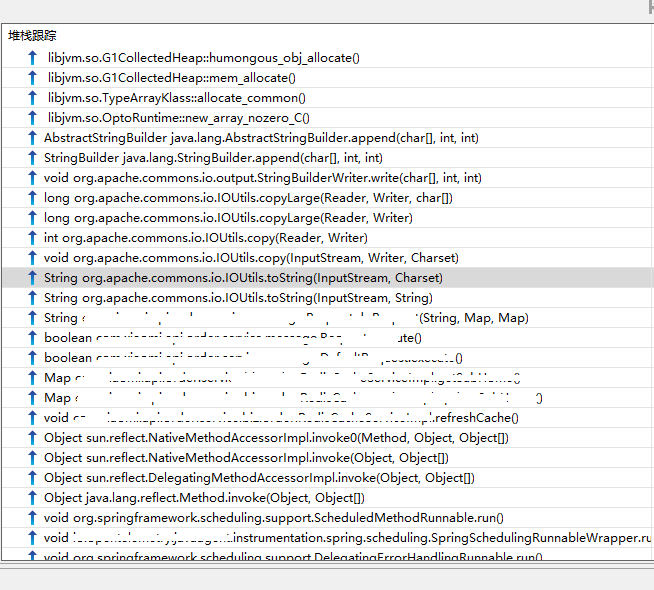
根据调用栈我发现,这是我们的一个定时任务,它会定时调用一个接口获取配置信息并缓存它,而这个接口返回的数据量达14M之多。
难道是这个接口导致的gc问题?但这个定时任务调用也不频繁呀,5分钟才调用一次,不至于让gc忙不过来吧! 另一个疑问是,这个定时任务在其它环境也会运行,而且其它环境的业务流量大得多,为什么其它环境没有问题?
至此,我也不确定是这个定时任务导致的问题,还是系统自身特点导致偶尔的高gc耗时。
由于我们有固定的上线日,于是我打算先优化产生大对象的代码,然后在上线前的期间试着优化一下jvm gc参数。
优化产生大对象的代码
我们使用的是httpclient调用接口,调用接口时,代码会先将接口返回数据读取成String,然后再使用jackson把String转成map对象,简化如下:
rsp = httpClient.execute(request);
String result = IOUtils.toString(rsp.getEntity().getContent());
Map resultMap = JSONUtil.getMapper().readValue(result, Map.class);
要优化它也很简单,使用jackson的readValue有一个传入InputStream的重载方法,用它来读取json数据,而不是将其加载成一个大的String对象再读,如下:
rsp = httpClient.execute(request);
InputStream is = rsp.getEntity().getContent();
Map resultMap = JSONUtil.getMapper().readValue(is, Map.class);
注:这里面map从逻辑上来说是一个大对象,但对jvm来说,它只是很多个小对象然后用指针连接起来而已,大对象一般由大数组造成,大String之所以是大对象,是因为它里面有一个很大的char[]数组。
优化GC参数
优化完代码后,我开始研究优化jvm gc参数了,我们使用的是jdk8,垃圾收集器是g1。
- g1是分region收集的,但region也分年轻代与老年代。
- g1的gc分
young gc与mixed gc,young gc用于收集年轻代region,mixed gc会收集年轻代与老年代region。 - 在
mixed gc回收之前,需要先经历一个并发周期(Concurrent Cycles),用来标记各region的对象存活情况,让mixed gc可以判断出需要回收哪些region。 - 并发周期分为如下4个子阶段: a. 初始标记(initial marking) b. 并发标记(concurrent marking) c. 重新标记(remarking) d. 清理(clean up) 需要注意的是,初始标记(initial marking)这一步是借助young gc完成的。
在g1中,young gc几乎没有什么可调参数,而mixed gc有一些,常见如下:
| 参数 | 作用 |
|---|---|
| -XX:InitiatingHeapOccupancyPercent | 开始mixed gc并发周期的堆占用阈值,当大于此比例,启动并发周期,默认45% |
| -XX:ConcGCThreads | 在并发标记时,使用多少个并发线程。 |
| -XX:G1HeapRegionSize | 每个region大小,当分配对象尺寸大于region一半时,才认为这是一个大对象。 |
| -XX:G1MixedGCLiveThresholdPercent | region存活比例,默认85%,当并发标记后发现region中存活对象比例小于这个值,mixed gc才会回收这个region,毕竟一个region如果都是存活的对象,那还有什么回收的必要呢。 |
| -XX:G1HeapWastePercent | 允许浪费的堆比例,默认5%,当可回收的内存比例大于此值时,mixed gc才会去执行回收,毕竟没什么可回收的对象时,还有什么回收的必要呢。 |
| -XX:G1MixedGCCountTarget | mixed gc执行的次数,一旦并发标记周期确认了回收哪些region后,mixed gc就进行回收,但mixed gc会分少量多次来回收这些region,默认8次。 |
| -XX:G1OldCSetRegionThresholdPercent | 每次mixed gc回收old region的比例,默认10%,如果G1MixedGCCountTarget是8的话,mixed gc整体能回收80%。 |
| -XX:G1ReservePercent | 堆保留空间比例,默认10%,这部分空间g1会保留下来,用来在gc时复制存活对象。 |
出现to-space exhausted会不会是mixed gc太慢了呢?于是我调整了如下参数:
- 让并发标记周期启动更早,运行得更快,将
-XX:InitiatingHeapOccupancyPercent从默认值45%调整到35%,-XX:ConcGCThreads从1调整为3。 -XX:G1MixedGCLiveThresholdPercent与-XX:G1HeapWastePercent确定回收哪些region,有多少比例垃圾才执行回收,我觉得它们的值本来就蛮激进,就没有调整。-XX:G1MixedGCCountTarget与-XX:G1OldCSetRegionThresholdPercent控制mixed gc执行多少次,每次回收多少region,我将-XX:G1OldCSetRegionThresholdPercent从10%调整到了15%,让它一次多回收些old region。- 增加保留空间,避免复制存活对象失败,将
-XX:G1ReservePercent从10%调整到20%。 - 尽量避免产生大对象,将
-XX:G1HeapRegionSize增加到16m。
于是我按照上面调整了jvm参数,可是第二天我发现还是有GC长耗时,次数也没有减少,看来问题根因和我调整的参数没有关系。
问题根因
就这样,到了上线日,于是我上线了前面优化大对象的代码,一天后,我发现偶尔的GC长耗时竟然没有了!
问题就这样解决了!!!
然而我心里还是有一个大大的问号,其它环境同样有这个定时任务,一样的运行频率,jvm配置也全是一样的,为啥其它环境没有问题呢?其它环境业务流量还大一些!
为此,我搜索了大量关于g1大对象的文章,我发现大对象的分配与回收过程有点特殊,如下:
- 大于region size一半的对象是大对象,会直接分配在old region,且gc时大对象不会被复制或移动,而是直接回收。
- 大对象回收发生在2个地方,一个是并发周期的clean up子阶段,另一个是young gc(这个特性在jdk8u60才加入)。
我忽然想到,莫非是俄罗斯环境流量太低,触发不了young gc,且并发周期又因为什么原因没执行,但定时任务又慢慢生成大对象将old region占满,导致了to-space exhausted?
于是,我打算写段代码试验一下,慢慢的只生成大对象,看g1会不会回收,如下:
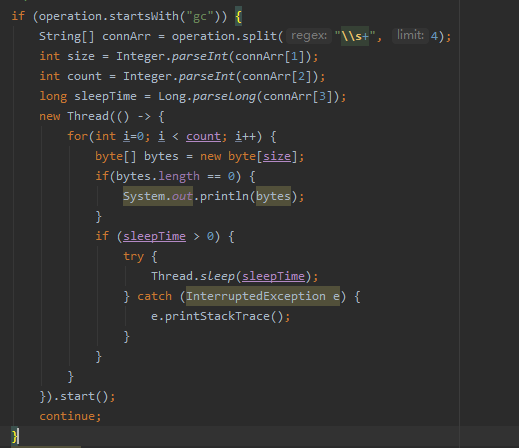
这个一个命令行交互程序,使用如下jvm参数启动它
# 1600m的堆,16m的region size
# rlwrap作用是使得这个命令行程序更好用
rlwrap java -server -Xms1600m -Xmx1600m -Xss1m -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=1g -Xloggc:/home/work/logs/applogs/gc-%t.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/work/logs/applogs/ -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy -XX:+UseG1GC -XX:G1LogLevel=finest -XX:G1HeapRegionSize=16m -XX:MaxGCPauseMillis=200 -jar command-cli.jar
用了1600M的堆,16M的region size,所以总共有100个region,jdk版本是1.8.0_222。 通过在这个交互程序中输入gc 9437184 20 0,可以生成20个9M的大对象。
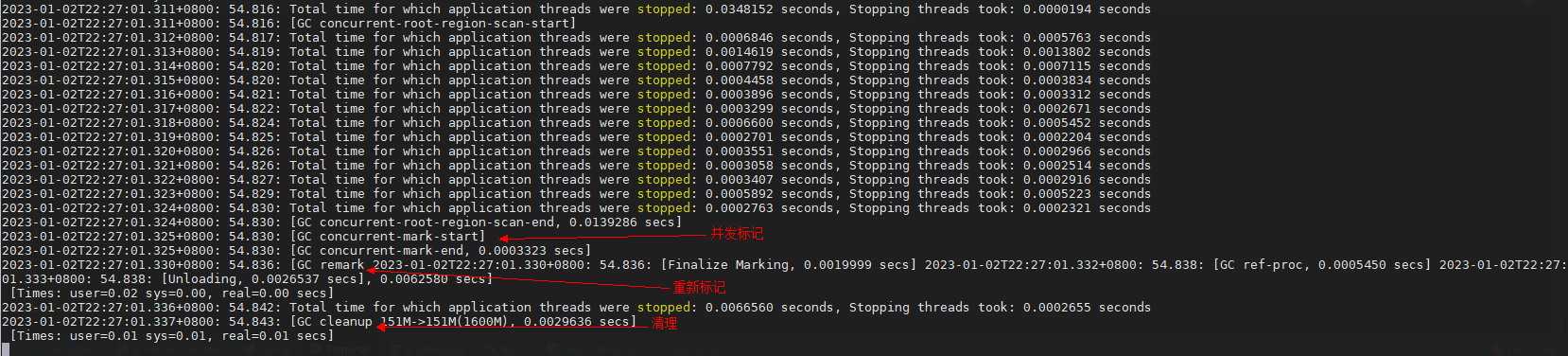
当我输入3次gc 9437184 20 0后,如下: 我从gc日志中发现了一次由initial marking触发的young gc,说明g1启动了并发周期,之所以发生young gc,是因为initial marking是借助ygc执行的。
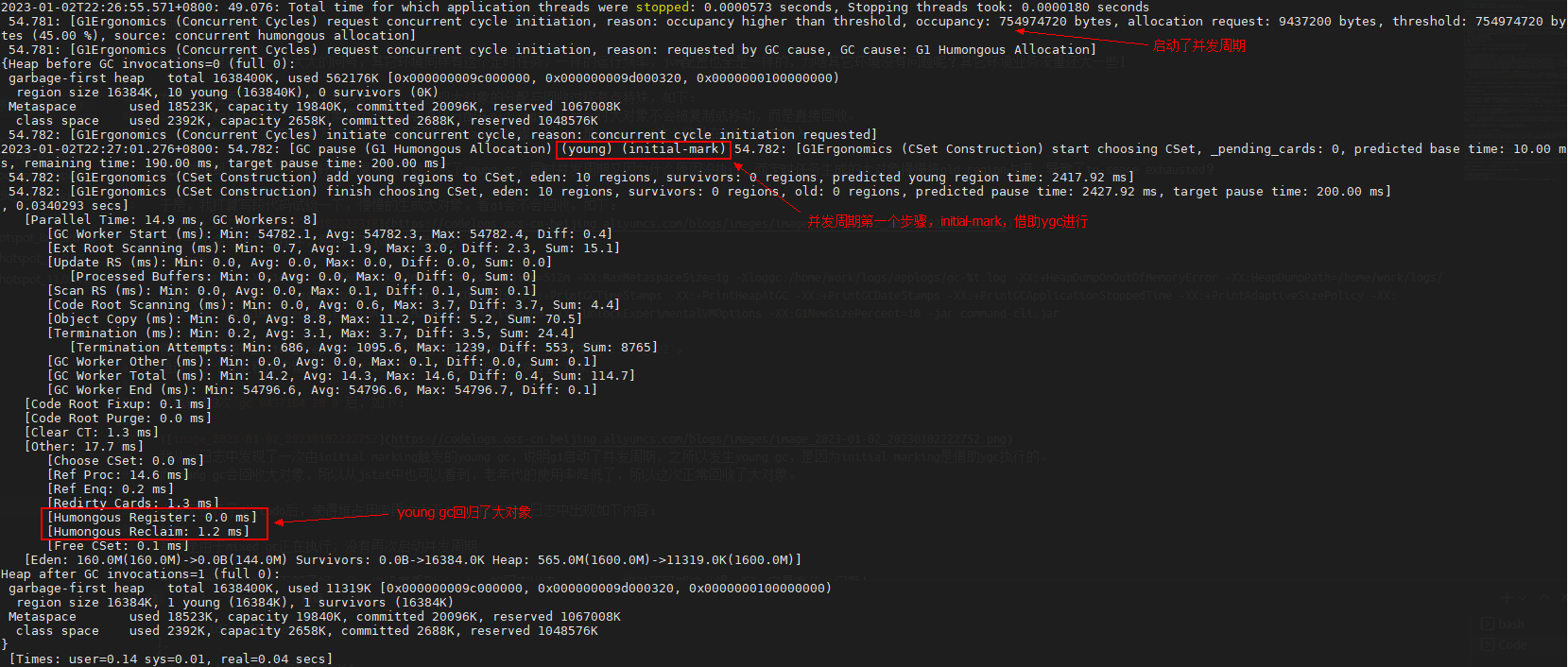
紧接着,我发现了并发标记、重新标记与清理阶段的日志。
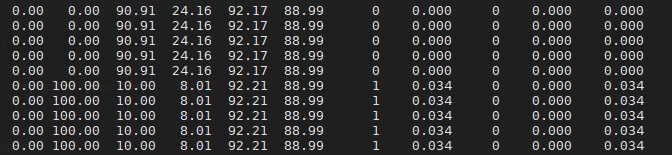
然后我在jstat中发现老年代使用率降低了,因为young gc会回收大对象,所以老年代使用率降低也是正常的
当我又执行了2次gc 9437184 20 0后,使得堆占用率再次大于45%,我发现gc日志中出现如下内容
看字面意思是,由于mixed gc正在执行,没有再次启动并发周期。
可是,我在这种状态下等了好久,也没有看到mixed gc的日志出来,不是说mixed gc正在执行嚒,它一定是有什么问题!
于是,我又执行了好几次gc 9437184 20 0,我在gc日志中发现了to-space exhausted!
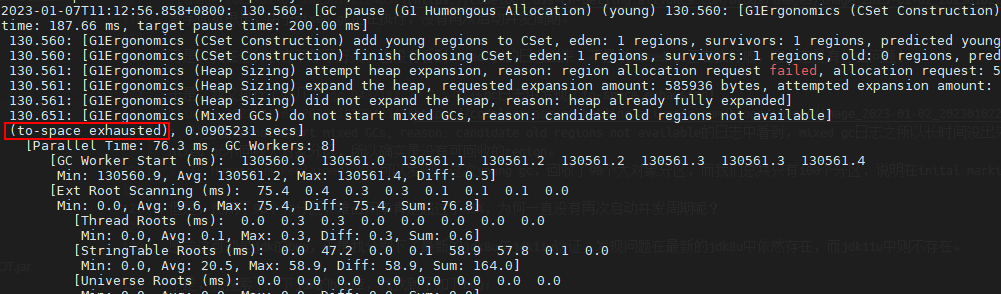
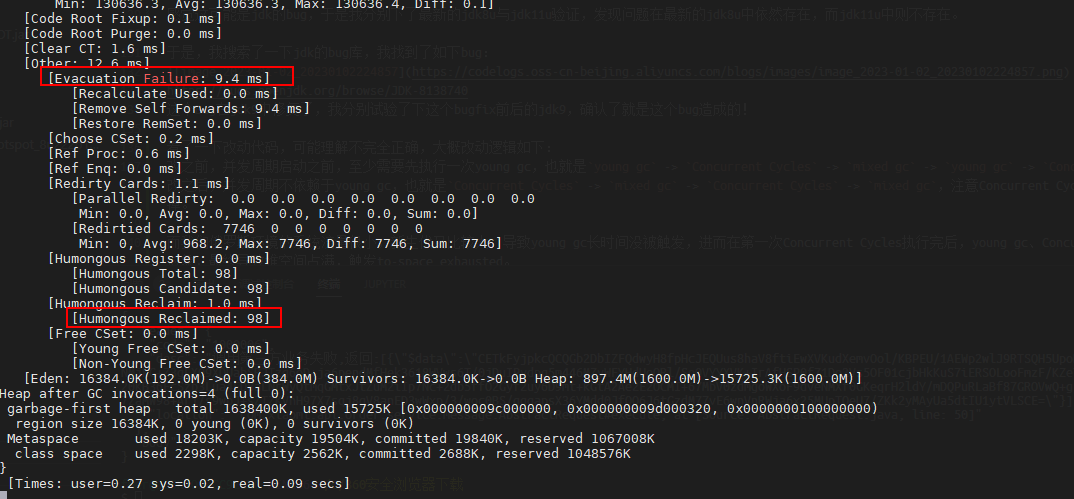
- 从上面do not start mixed GCs, reason: candidate old regions not available的日志中看到,mixed gc日志之所以长时间没出来,是因为没有可回收的region导致mixed gc没有执行,因为我们只创建了大对象,但mixed gc不回收大对象分区,所以确实是没有可回收的region的。
- 从
Humongous Reclaimed: 98可以发现,这次young gc,回收了98个大对象分区,而我们总共只有100个分区,说明在inital marking之后创建的大对象,确实一直都没有回收。
注:添加
-XX:G1LogLevel=finest参数,才能输出Humongous Reclaimed这一项。
但是,大对象分区占了98个,堆占用率肯定超过了45%,为何一直没有再次启动并发周期呢?
感觉这可能是jdk的bug,于是我分别下了最新的jdk8u与jdk11u验证,发现问题在最新的jdk8u中依然存在,而jdk11u中则不存在,这应该就是JDK的Bug!
于是我通过二分搜索法多次编译了不同版本的JDK,最终确定问题fix在jdk9_b93与jdk9_b94之间。
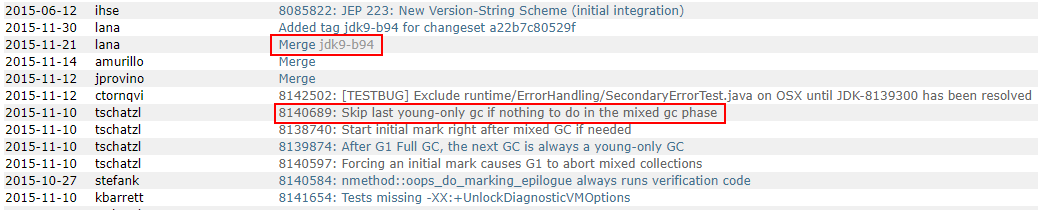
并在jdk的bug库中,搜索到了相同描述的bug反馈,如下:
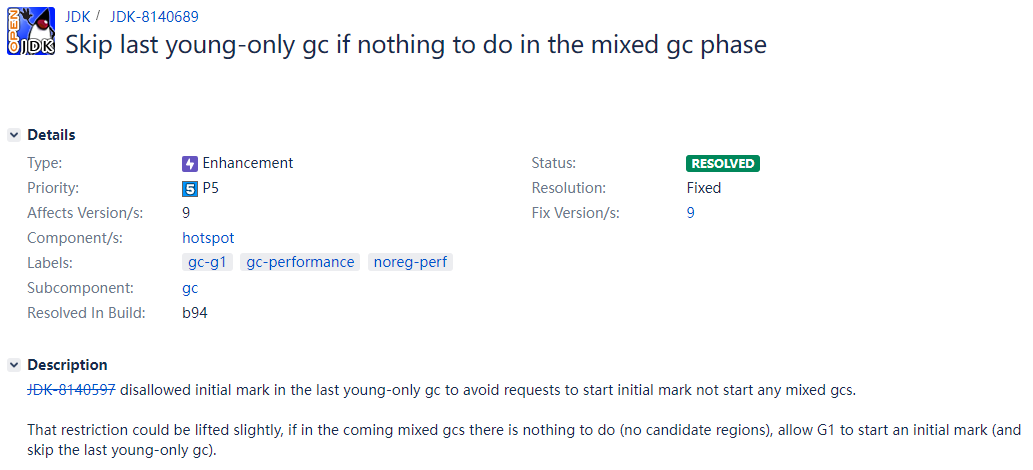
Bug链接:https://bugs.openjdk.org/browse/JDK-8140689
Bug改动代码如下
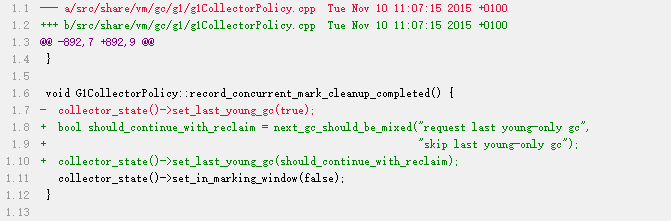
大致瞄了下代码,大体改动逻辑如下:
- G1再次启动并发周期之前,至少需要执行过一次
mixed gc或young gc,类似于Concurrent Cycles->mixed gc|young gc->Concurrent Cycles->mixed gc|young gc。 - 我们的场景是,在并发周期结束之后,由于没有需要回收的分区,导致mixed gc实际没有执行,可是我们只分配了大对象,且大对象又只分配在old region,所以young gc也不可能被触发,而由于上面的条件,
Concurrent Cycles也不会被触发,因此最终大对象将堆占满触发了to-space exhausted。 - 修复逻辑是,当并发周期结束后,没有需要回收的分区时,should_continue_with_reclaim=false,进而使得允许不执行纯young gc而直接启动并发周期,类似于
Concurrent Cycles->Concurrent Cycles。
所以在使用JDK8时,像那种系统流量很小,新生代较大,又有定时任务不断产生大对象的场景,堆几乎必然会被慢慢占满,要解决这个问题,可参考如下处理:
- 优化代码,避免分配大对象。
- 代码无法优化时,可考虑升级jdk11。
- 无法升级jdk11时,可考虑减小
-XX:G1MaxNewSizePercent让新生代小一点,让young gc能执行得更频繁些,同时老年代更大,能缓冲更多大对象分配。
考虑到我们负责的其它系统中,时不时就有一波大响应体的请求,也没法快速修改代码,于是我统一将-XX:G1MaxNewSizePercent减小到30%,经过观察,修改后GC频率有所增加,但暂停时间有所下降,这是符合期望的。
问题总结
当我在jdk的bug库中搜索问题时,发现不少和G1大对象相关的优化,早期JDK(如JDK8)的G1实现可能在大对象回收上不太完善,所以写代码时要注意尽量少创建大对象,以回避这些隐性问题。
写在最后
在冰河的知识星球有大量从零开始带你手写的企业级生产项目,像DeepSeek大模型、手写高性能熔断组件、手写通用指标上报组件、手写高性能数据库路由组件、分布式IM即时通讯系统、Sekill分布式秒杀系统、手写RPC、简易商城系统等等,这些项目的需求、方案、架构、落地等均来自互联网真实业务场景,让你真正学到互联网大厂的业务与技术落地方案,并将其有效转化为自己的知识储备。
值得一提的是:冰河自研的Polaris高性能网关比某些开源网关项目性能更高,并且冰河也正在为企业级高性能RPC框架录制视频,全程带你分析原理和手撸代码。 你还在等啥?不少小伙伴经过星球硬核技术和项目的历练,早已成功跳槽加薪,实现薪资翻倍,而你,还在原地踏步,抱怨大环境不好。抛弃焦虑和抱怨,我们一起塌下心来沉淀硬核技术和项目,让自己的薪资更上一层楼。
目前,领券加入星球就可以跟冰河一起学习《DeepSeek大模型》、《手写高性能通用熔断组件项目》、《手写高性能通用监控指标上报组件》、《手写高性能数据库路由组件项目》、《手写简易商城脚手架项目》、《手写高性能RPC项目》和《Spring6核心技术与源码解析》、《实战高并发设计模式》、《分布式Seckill秒杀系统》、《分布式IM即时通讯系统》和《手写高性能Polaris网关》,从零开始介绍原理、设计架构、手撸代码。
花很少的钱就能学这么多硬核技术、中间件项目和大厂秒杀系统与分布式IM即时通讯系统,比其他培训机构不知便宜多少倍,硬核多少倍,如果是我,我会买他个十年!
加入要趁早,后续还会随着项目和加入的人数涨价,而且只会涨,不会降,先加入的小伙伴就是赚到。
另外,还有一个限时福利,邀请一个小伙伴加入,冰河就会给一笔 分享有奖 ,有些小伙伴都邀请了50+人,早就回本了!
其他方式加入星球
- 链接 :打开链接 http://m6z.cn/6aeFbs 加入星球。
- 回复 :在公众号 冰河技术 回复 星球 领取优惠券加入星球。
特别提醒: 苹果用户进圈或续费,请加微信 hacker_binghe 扫二维码,或者去公众号 冰河技术 回复 星球 扫二维码加入星球。
联系冰河
加群交流
本群的宗旨是给大家提供一个良好的技术学习交流平台,所以杜绝一切广告!由于微信群人满 100 之后无法加入,请扫描下方二维码先添加作者 “冰河” 微信(hacker_binghe),备注:星球编号。

公众号
分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。内容在 冰河技术 微信公众号首发,强烈建议大家关注。

视频号
定期分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。

星球
加入星球 冰河技术,可以获得本站点所有学习内容的指导与帮助。如果你遇到不能独立解决的问题,也可以添加冰河的微信:hacker_binghe, 我们一起沟通交流。另外,在星球中不只能学到实用的硬核技术,还能学习实战项目!
关注 冰河技术公众号,回复 星球 可以获取入场优惠券。

好了,今天就到这儿吧,我是冰河,我们下期见~~
